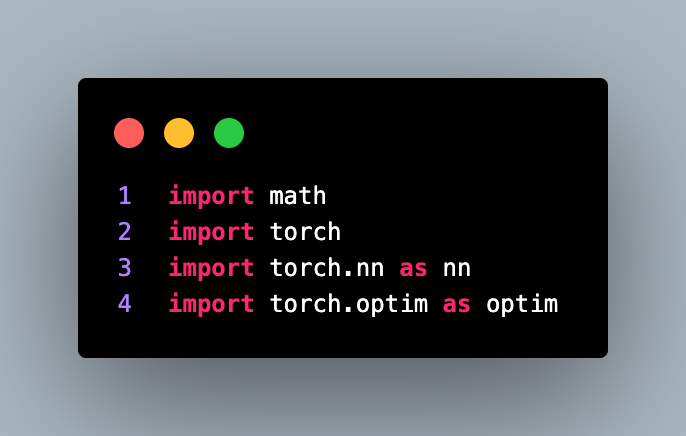
Here we begins by importing necessary libraries: math, torch, torch.nn, and torch.optim. These libraries provide mathematical functions, tensor operations, neural network components, and optimization algorithms required for building the transformer-based language model
Next, several hyperparameters are defined: vocab_size: This represents the size of the vocabulary, i.e., the number of unique tokens in the language, d_model: It specifies the dimensionality of the model. It determines the size of the token embeddings and the hidden states throughout the model, n_heads: This determines the number of attention heads used in the self-attention mechanism. More attention heads allow the model to focus on different parts of the input sequence simultaneously, dim_feedforward: It denotes the dimensionality of the feedforward layers. These layers process the outputs of the self-attention mechanism and introduce non-linearity into the model, num_layers: This indicates the number of transformer blocks in the model. Each block consists of a self-attention layer and a feedforward layer, num_epochs: The number of training epochs, i.e., the number of times the entire dataset will be passed through the model during training, learning_rate: It represents the learning rate used by the Adam optimizer, which controls the step size during gradient-based optimization
These hyperparameters can be adjusted according to the specific requirements and constraints of the task at hand. They influence the model's capacity, convergence speed, and generalization ability.
After defining the hyperparameters, the code saves them in a text file for future reference. Each hyperparameter value is written to a separate line in the file
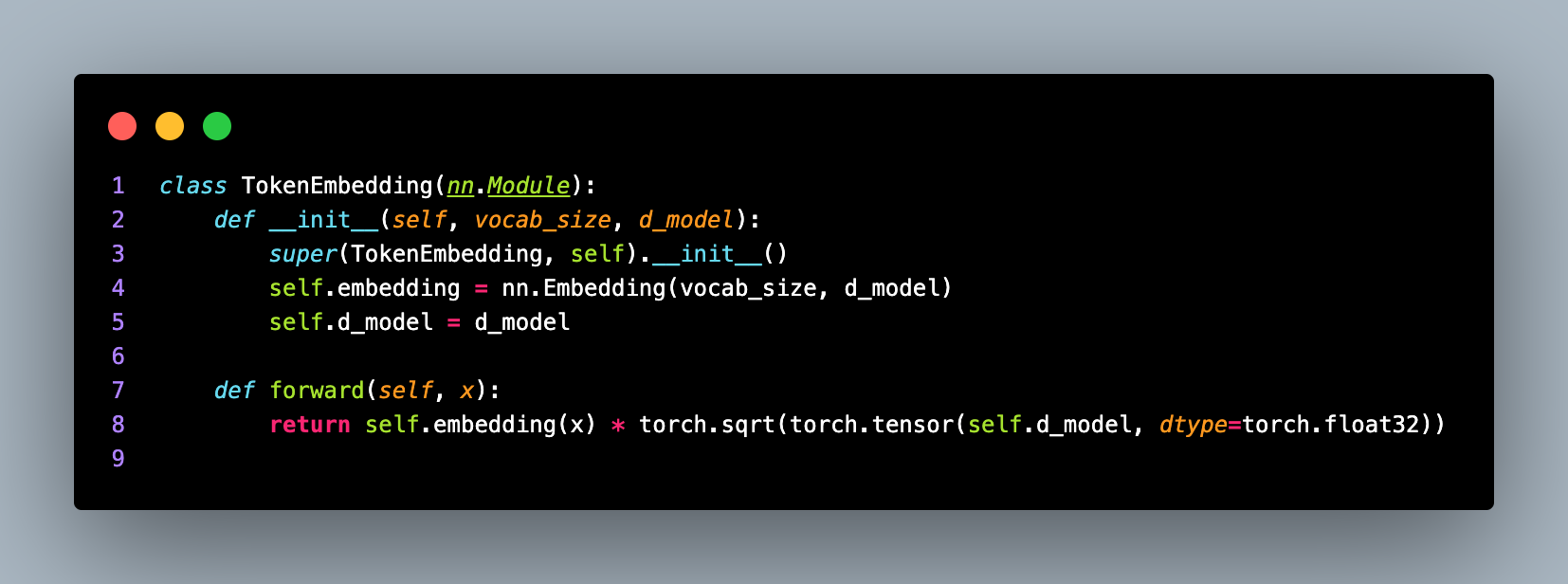
Next, the code defines the TokenEmbedding class, which handles the token embedding process. Token embedding is a crucial step in NLP tasks, where each token in a sequence is mapped to a continuous vector representation, allowing the model to capture semantic and contextual information.
The TokenEmbedding class is a subclass of torch.nn.Module and takes vocab_size and d_model as input parameters. It initializes an embedding layer (nn.Embedding) with the specified vocabulary size and model dimensionality. The embedding layer maps each token index to a dense vector representation.
The forward method of the TokenEmbedding class takes an input tensor x representing the token indices and applies the embedding layer to it. Additionally, it scales the embeddings by multiplying them with the square root of the model's dimensionality. Scaling the embeddings helps in stabilizing the training process.
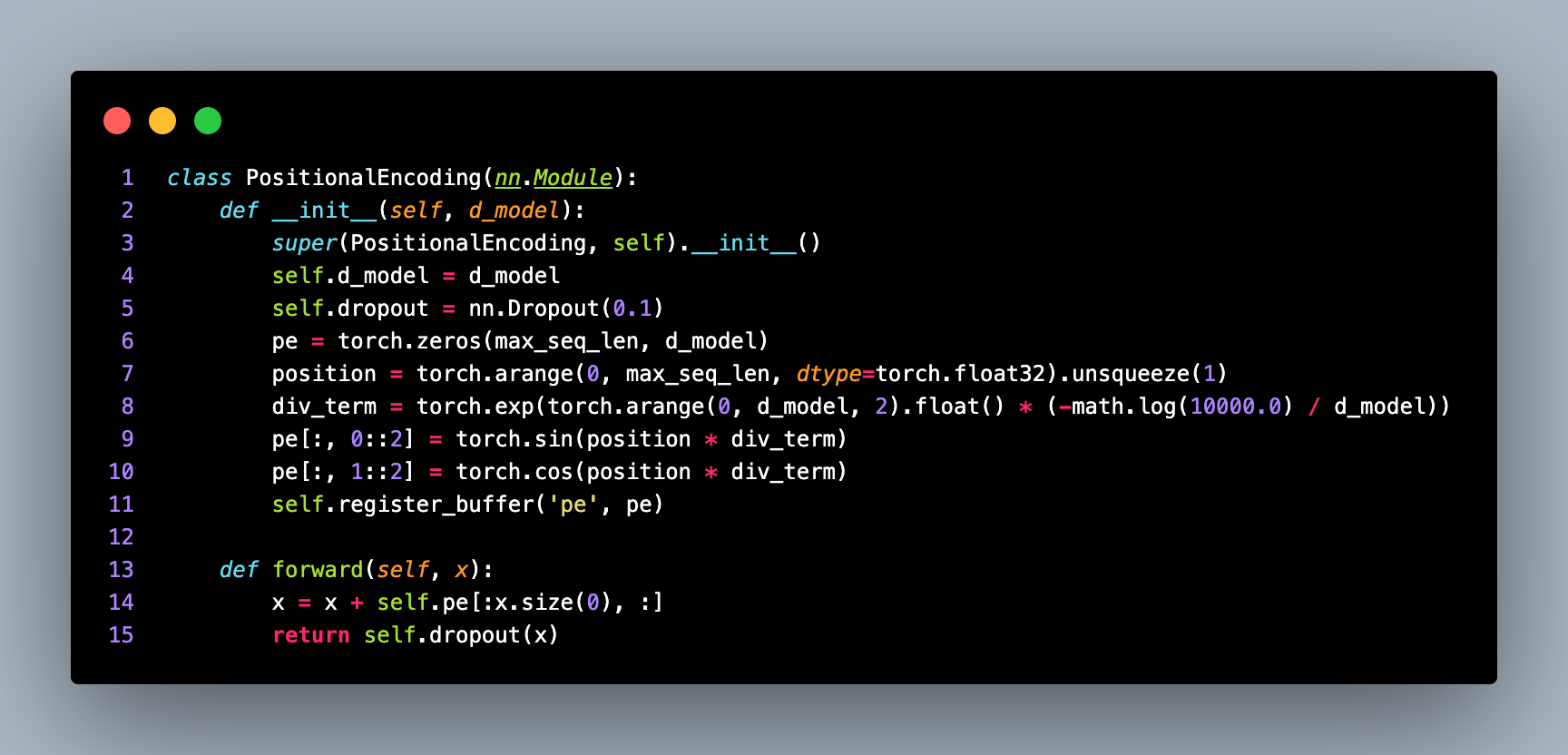
After defining the TokenEmbedding class, the code proceeds to define the PositionalEncoding class, which implements the positional encoding mechanism introduced in the "Attention Is All You Need" paper. Positional encoding is used to inject information about the relative and absolute positions of tokens into the transformer model.
The PositionalEncoding class is a subclass of torch.nn.Module and takes d_model as an input parameter, representing the model's dimensionality.
Within the __init__ method, the class initializes the model's dimensionality, sets a dropout layer, and creates a positional encoding matrix pe. The positional encoding matrix pe has a shape of (1000, d_model). The number 1000 represents the maximum sequence length that the model can handle, which can be adjusted based on the specific requirements. The matrix is filled with zeros initially.
Next, two tensors are created: position and div_term. The position tensor represents the positions from 0 to 999, indicating the relative positions of tokens in the sequence. The div_term tensor is used to calculate the scaling factor for the positional encoding values. The positional encoding values are computed using sine and cosine functions applied to the position and div_term tensors. The values are then assigned to the pe tensor. The even dimensions of pe are filled with the sine values, while the odd dimensions are filled with the cosine values.
The register_buffer method is used to register the pe tensor as a buffer, ensuring that it is saved and loaded along with the model's parameters.
The forward method of the PositionalEncoding class takes an input tensor x and performs the positional encoding. It adds the positional encoding values to the input tensor x and applies dropout to the resulting tensor.
The positional encoding values are added to the input tensor x using broadcasting. The self.pe[:x.size(0), :] expression selects the positional encoding values corresponding to the length of the input sequence. The resulting tensor is then passed through a dropout layer for regularization.
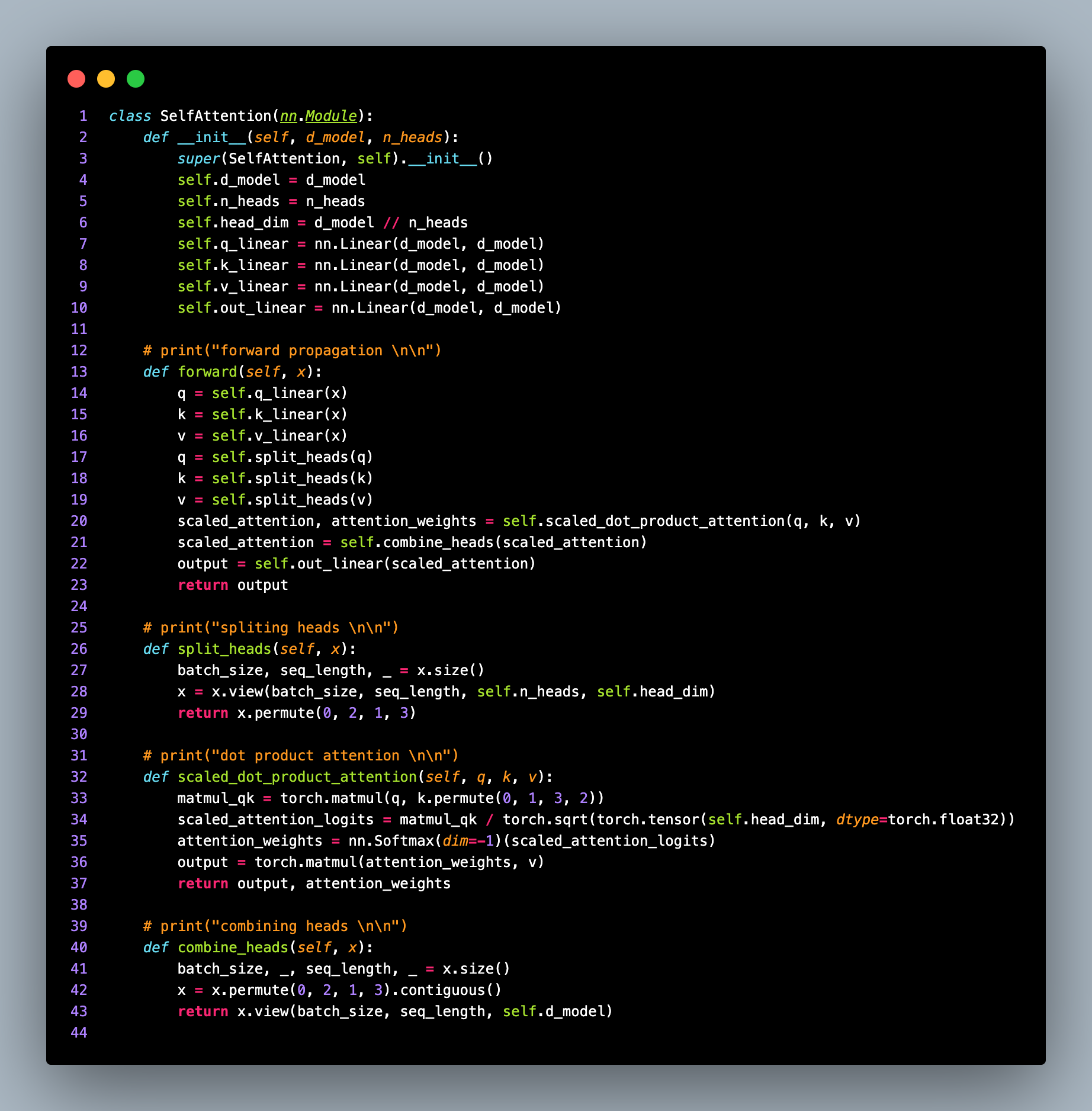
This completes the explanation of the PositionalEncoding class. Next, we move on to the SelfAttention class, which represents the self-attention layer in the transformer model.
The SelfAttention class takes d_model and n_heads as input parameters, representing the model's dimensionality and the number of attention heads, respectively.
Within the __init__ method, the class initializes various linear layers (nn.Linear) required for the self-attention mechanism. These layers transform the input tensor to the query (q_linear), key (k_linear), and value (v_linear) spaces. The out_linear layer is used to project the attention outputs back to the original dimensionality
The forward method of the SelfAttention class performs the forward propagation of the self-attention layer.
The input tensor x is transformed into query (q), key (k), and value (v) representations using the linear layers.
The split_heads method is called to split the query, key, and value tensors into multiple heads. This splitting is necessary to enable parallelization and enable each attention head to focus on different parts of the input sequence.
The split_heads method reshapes the input tensor x to have dimensions (batch_size, seq_length, n_heads, head_dim). The head_dim is calculated as the model's dimensionality divided by the number of attention heads. The dimensions are permuted to move the head dimension before the sequence length dimension.
Next, the scaled_dot_product_attention method is called to compute the attention weights and the scaled attention values.
The scaled_dot_product_attention method calculates the attention scores by performing matrix multiplication between the query tensor q and the key tensor k. The attention scores are then divided by the square root of the head_dim to scale them.
The attention scores are passed through a softmax function to obtain attention weights that represent the importance of each token in the input sequence. These attention weights are then used to compute the weighted sum of the value tensor v to obtain the attention outputs.
After obtaining the attention outputs, the combine_heads method is called to concatenate the attention heads and reshape them to the original dimensionality.
The combine_heads method permutes the dimensions of the attention heads tensor x to bring the head dimension back to its original position. The tensor is then reshaped to have dimensions (batch_size, seq_length, d_model).
After discussing the SelfAttention class, we move on to the FeedForward class, which represents the feedforward layer within the transformer model.
he FeedForward class takes d_model and dim_feedforward as input parameters.
Within the __init__ method, the class defines two linear layers (nn.Linear) followed by a ReLU activation function. These layers introduce non-linearity into the model and facilitate the transformation of the input tensor.
The forward method performs the forward propagation of the feedforward layer. The input tensor x is passed through the first linear layer (linear1), followed by the ReLU activation function (relu). Then, the output is passed through the second linear layer (linear2). The final output is returned.
Next, we come to the TransformerBlock class, which represents a single transformer block within the transformer model.
The TransformerBlock class takes d_model, n_heads, and dim_feedforward as input parameters.
Within the __init__ method, the class initializes the self-attention layer (self_attention), the feedforward layer (feedforward), and two layer normalization layers (norm1 and norm2). Layer normalization is used to normalize the inputs at each layer, aiding in stable and effective training.
The forward method performs the forward propagation of the transformer block. The input tensor x is passed through the self-attention layer, and the resulting attention output is added to the input tensor. This residual connection helps preserve important information from the input.
After the addition, layer normalization (norm1) is applied to the tensor. Then, the tensor is passed through the feedforward layer, and the resulting output is added to the tensor again. Another layer normalization (norm2) is applied before returning the final output. This completes the explanation of the FeedForward class and the TransformerBlock class.
Next, we move on to the Transformer class, which represents the overall transformer model.
The Transformer class takes vocab_size, d_model, n_heads, dim_feedforward, and num_layers as input parameters. Within the __init__ method, the class initializes the token embedding layer (token_embedding) using the TokenEmbedding class. It also initializes the positional encoding layer (positional_encoding) using the PositionalEncoding class.
The transformer blocks are created using the TransformerBlock class. The number of blocks is determined by num_layers. The transformer blocks are stored in a nn.ModuleList to ensure they are registered as sub-modules.
A linear layer (fc) is defined to project the output tensor to the vocabulary size. This layer provides the logits for each token in the vocabulary.
The forward method of the Transformer class performs the forward propagation of the transformer model.
The input tensor x is first passed through the token embedding layer (token_embedding), followed by the positional encoding layer (positional_encoding).
Then, the input tensor is sequentially passed through each transformer block in the transformer_blocks list. Each transformer block applies self-attention, feedforward layers, and layer normalization. Finally, the output tensor is passed through the linear layer (fc), which produces the logits for each token in the vocabulary. The logits represent the predicted probability distribution over the vocabulary. This completes the explanation of the Transformer class. In the next part, we will cover the dataset loading, tokenization, model initialization, loss function, optimizer, training loop, and saving the trained model.
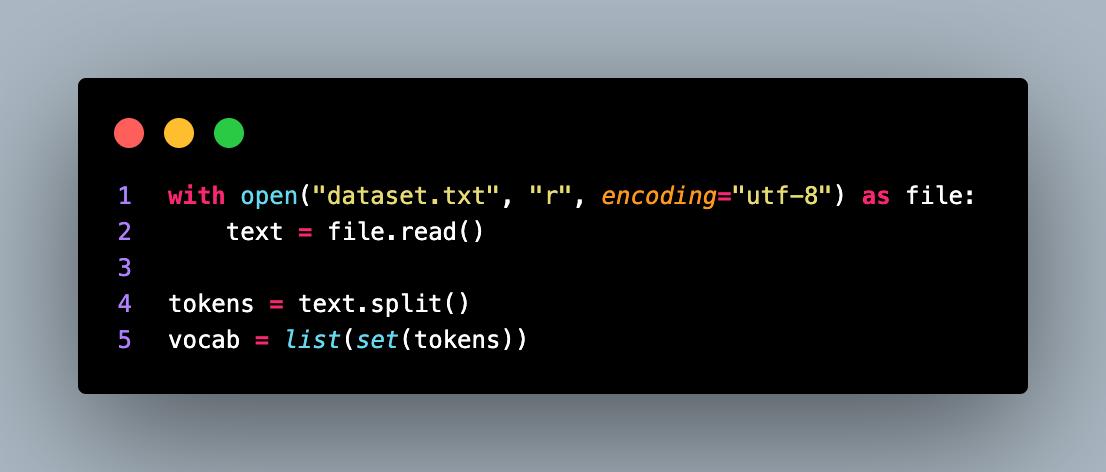
After that we move on to the remaining part of the code, which includes dataset loading, tokenization, model initialization, loss function, optimizer, training loop, and saving the trained model. First, the code loads the dataset from a file. The contents of the file are read and stored in the text variable.
The code then proceeds to create a vocabulary from the dataset. It splits the text into tokens and extracts unique tokens to form the vocabulary. The vocabulary size is determined by the number of unique tokens.
The tokens list contains all the individual tokens extracted from the text. The vocab list stores the unique tokens present in the tokens list. The vocab_size variable represents the number of unique tokens in the vocabulary.
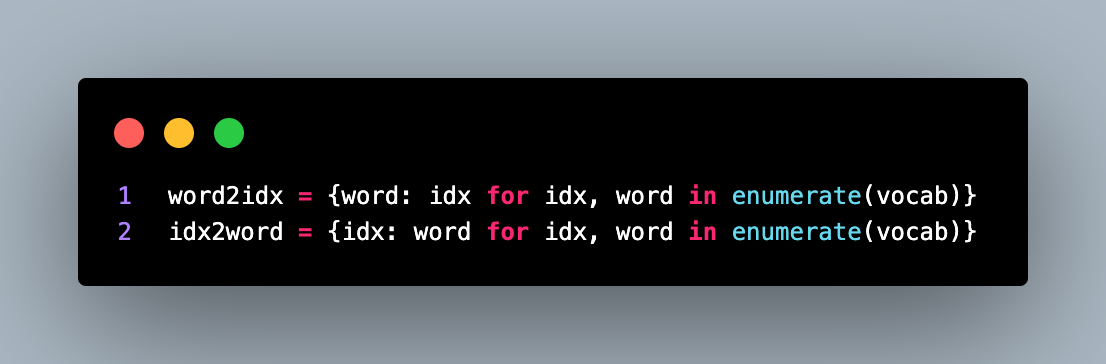
Two dictionaries, word2idx and idx2word, are created to map tokens to their corresponding indices and vice versa. These mappings are useful for encoding and decoding text during tokenization and text generation processes.
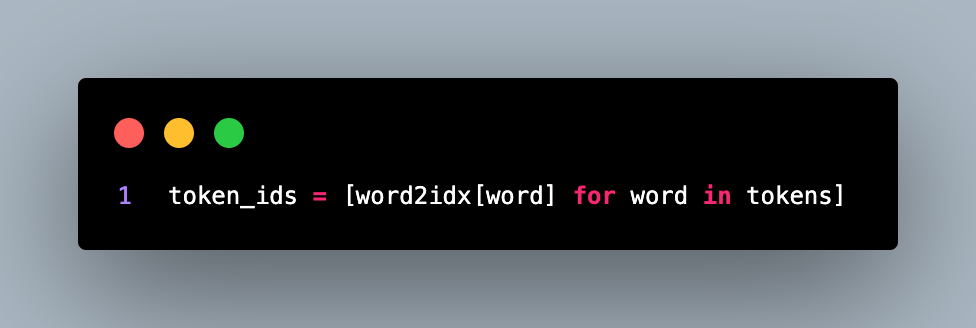
Next, the code proceeds to tokenization. It converts the text into a sequence of token indices using the word2idx mapping.
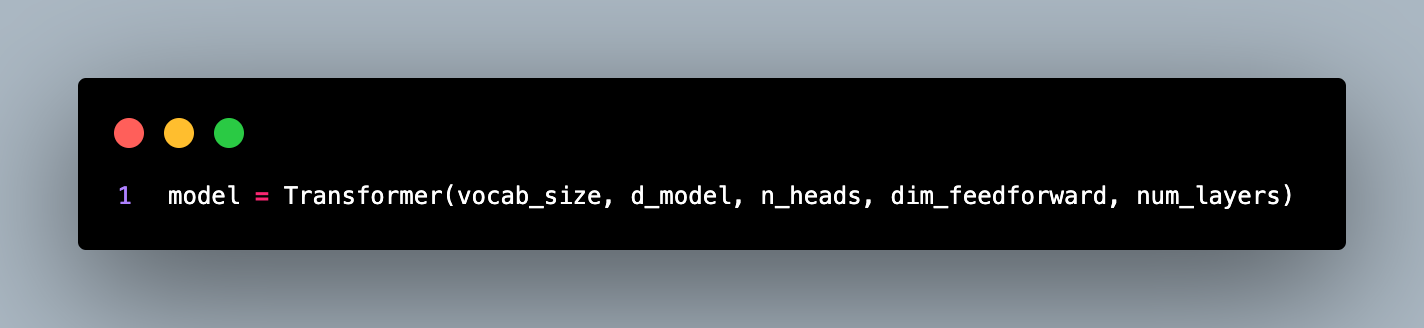
The token_ids list contains the indices of tokens in the vocabulary corresponding to the tokens in the tokens list. After tokenization, the code initializes the transformer model using the Transformer class.
The model takes the vocab_size, d_model, n_heads, dim_feedforward, and num_layers as input parameters. Next, the code defines the loss function and the optimizer. The loss function is set to nn.CrossEntropyLoss(), which is suitable for multi-class classification tasks.
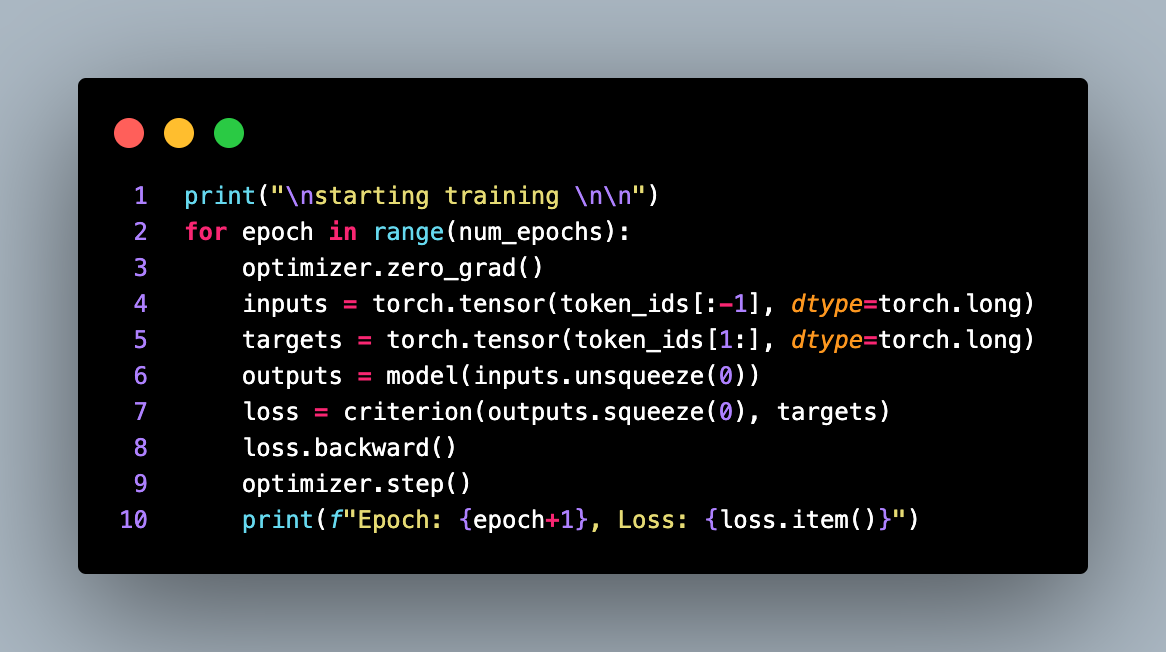
The optimizer is set to Adam, and the learning rate is initialized to the specified learning_rate. The code then enters the training loop, which iterates over the specified number of epochs.
In each epoch, the optimizer gradient is zeroed using optimizer.zero_grad(). The input and target tensors are created by converting the token indices to PyTorch tensors.
The model is then called with the input tensor, inputs.unsqueeze(0), to obtain the output logits. The loss is calculated by comparing the output logits with the target tensor using the defined criterion (CrossEntropyLoss).
The loss is backpropagated through the model using loss.backward(), and the optimizer step is performed using optimizer.step() to update the model parameters.
During training, the epoch number and the corresponding loss are printed.
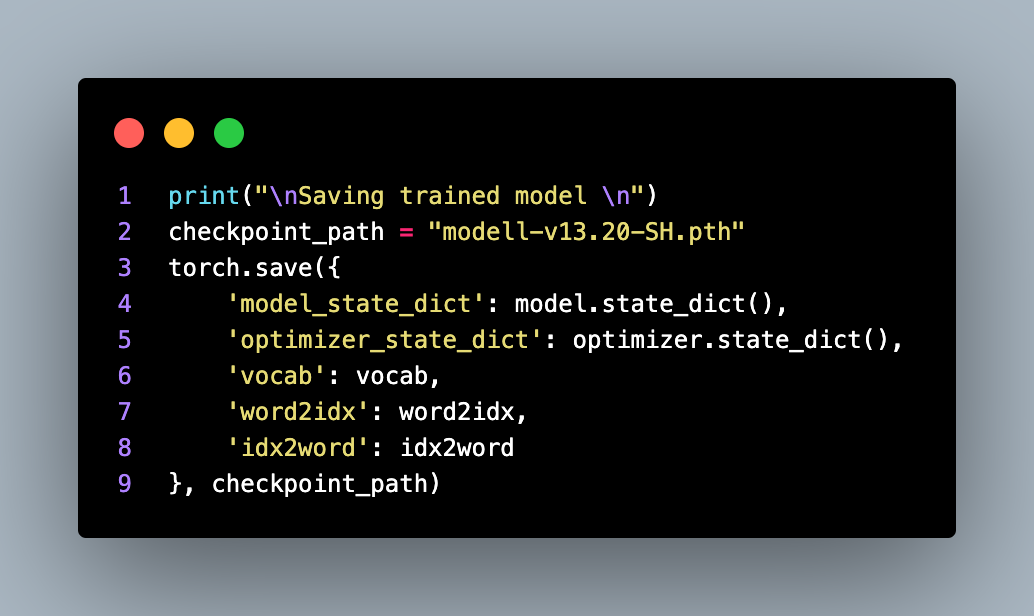
After the training loop completes, the trained model is saved for future use.
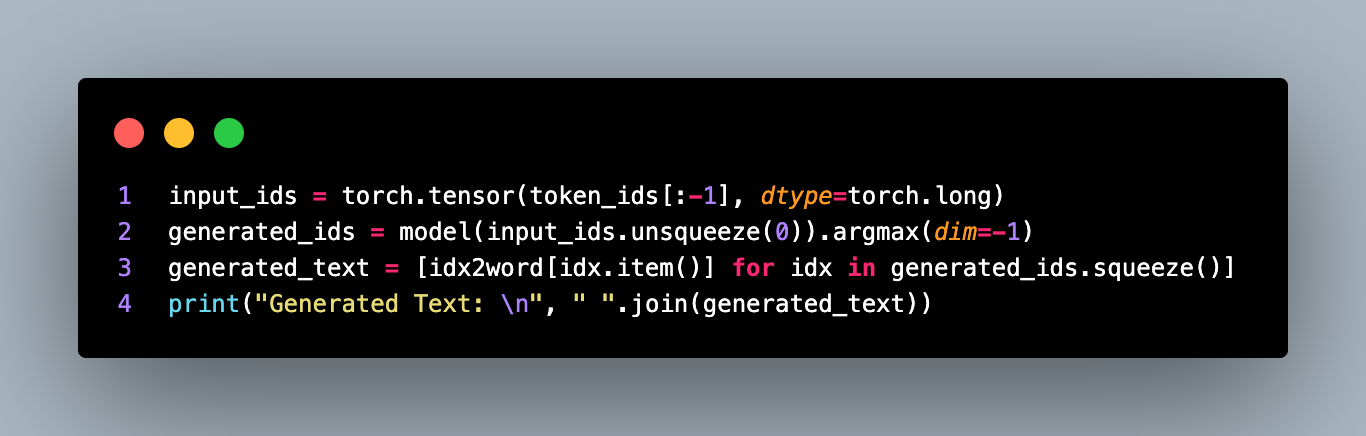
The trained model's state dictionary, along with the optimizer state, vocabulary, and token index mappings, is saved in a checkpoint file at the specified checkpoint_path. Finally, an example generation is performed using the trained model. An input tensor is created using the token indices, and the model is called to generate the predicted token indices.
The input_ids tensor is passed through the model, and the token indices with the highest probability are selected using argmax(dim=-1). These indices are then converted back to their corresponding tokens using the idx2word mapping.
The generated text, consisting of the predicted tokens, is printed. This completes the explanation of the remaining part of the code.